
Pydantic AI vs. Instructor: Structured LLM Output
If you've been keeping tabs on the structured output LLM tooling scene, you might have noticed the explosive rise of pydantic-ai. From practically zero stars to a rocket-like ascent in just a few months, it's quickly become a favorite in the Python community.
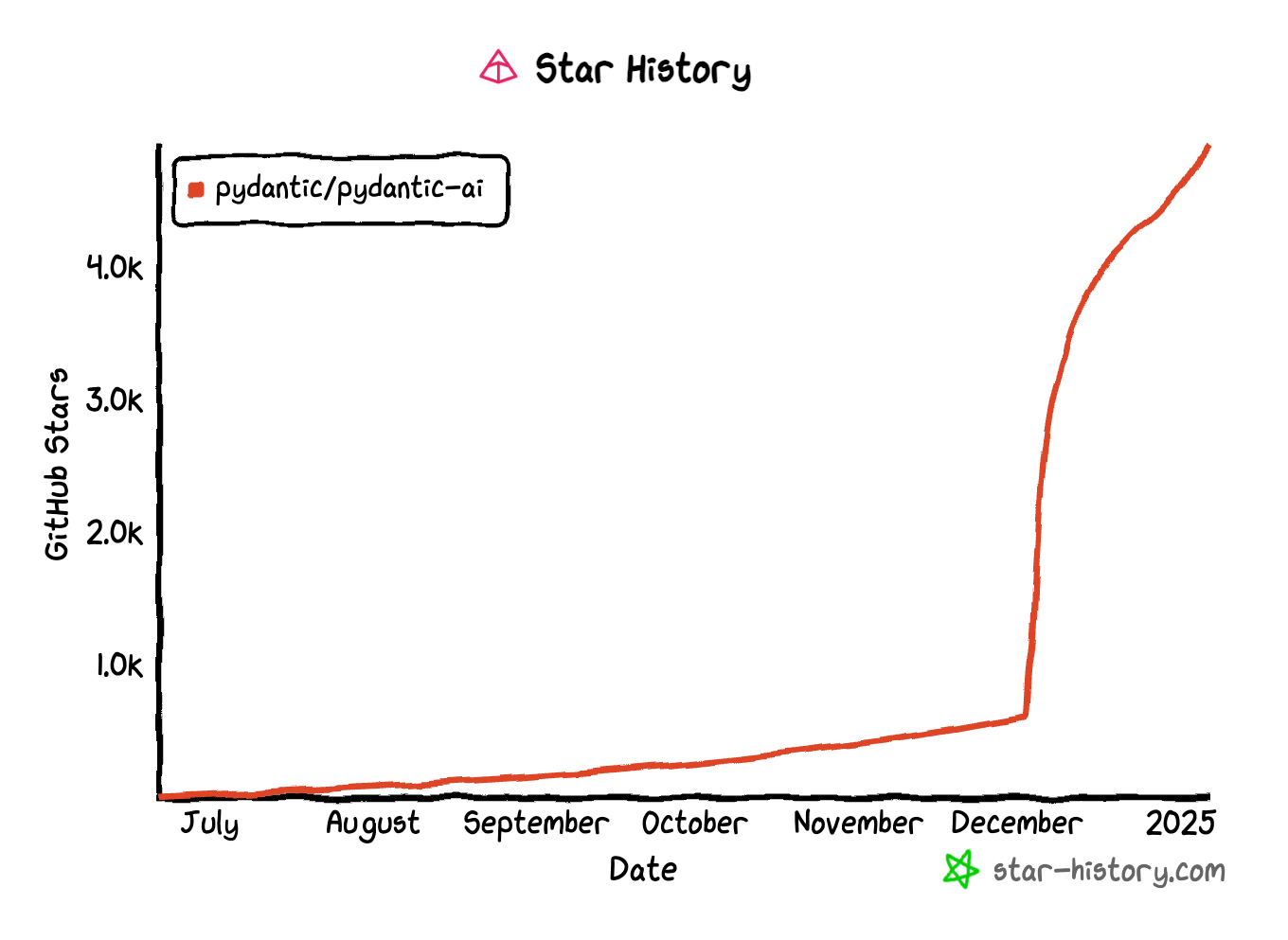
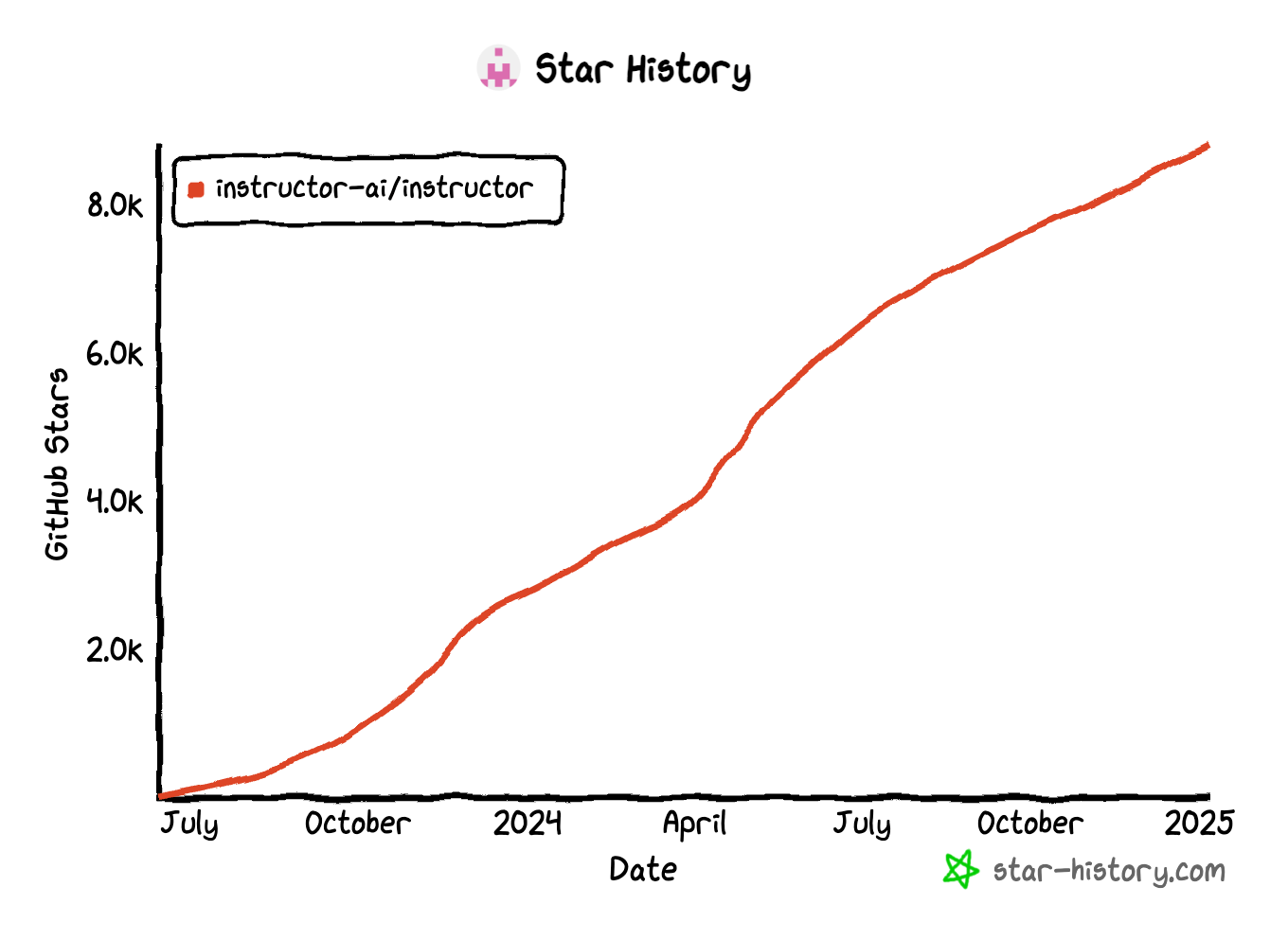
Compare that to Jason Liu's instructor, which has been steadily gaining stars since its launch in July 2023. Both tools aim to solve a common pain point with LLMs—structured output. So, what's driving this disparity? More importantly, which one should you use to wrangle structured output from large language models (LLMs)?
Let's break it down (not a Jomboy reference).
The Classic Problem: Getting Predictable JSON Out of LLMs
LLMs love to ramble (so do I, to be fair). Ask for JSON, and you might get something that looks like JSON—until it doesn't. Validating, correcting, and shaping output has been a headache since day one. Anyone remember prefilling the start of the LLM response with a { or [ { to give the model the hint? Simple tasks like extracting user data or filling structured reports can quickly turn into debugging nightmares.
Structured output is critical when working with LLMs in production. When generating content for APIs, reports, or structured logs, inconsistencies can lead to broken pipelines, failed validations, and hours spent writing regex to clean up the mess.
Enter instructor and pydantic-ai: both designed to solve the same problem—generating reliable, structured data from LLM responses. But they take different approaches under the hood, each with unique strengths and trade-offs.
pydantic-ai: The New Hotness
Pros:
- Direct Integration with Pydantic: If you're already using Pydantic models for validation, this is and feels like a natural extension. Define your model, and
pydantic-aiwill ensure the LLM output conforms. Being created by the same team as Pydantic, it offers seamless native compatibility. - Strict Enforcement: It doesn't just request structured output; it validates it against your schema, correcting errors where possible.
- Error Correction: If the model output doesn't match your schema,
pydantic-aiattempts to correct it. - Rapid Growth: The star history doesn't lie—devs are flocking to it, and fast. Likely due to the strong developer mindshare around Pydantic in the Python world.
Cons:
- Early Growth Risks: With rapid adoption comes the risk of bugs and API churn.
- Validation-First Mindset: Great for strict use cases but can be overkill for casual or exploratory LLM tasks.
Supported LLMs and Vendors:
Both libraries allow users to swap models/vendors in and out, though pydantic-ai supports fewer models at the time of writing (January 2025) given it's had less time to develop model support. Here's a snapshot of supported models:
- OpenAI models (GPT-3.5, GPT-4)
- Anthropic Claude (as of December 2024)
- Azure OpenAI Service
- AWS Bedrock (limited unofficial support)
Example Usage:
from pydantic_ai import OpenAI
from pydantic import BaseModel
class UserModel(BaseModel):
name: str
age: int
openai_client = OpenAI(model="gpt-4")
response = openai_client.chat(
messages=[{"role": "user", "content": "Tell me about John, age 30."}],
response_model=UserModel
)
print(response)
instructor: The Battle-Tested (Nearly 2-Year-Old) Veteran
Pros:
- Simpler API: Aimed at being minimal and elegant. Less boilerplate if you're just trying to get structured responses without a full validation layer.
- Steady Growth: The slower, steadier rise in stars suggests a core user base that values stability and long-term support.
- More Flexibility: Works well for exploratory tasks where minor inconsistencies aren't dealbreakers.
Cons:
- Weaker Validation Guarantees: It's more about guiding the model than strictly enforcing output structure.
- Less Ecosystem Integration: Doesn't tie as deeply into existing tools like Pydantic does.
Supported LLMs and Vendors:
instructor supports more models and vendors out of the box, making it a more versatile choice for users working across different platforms or less popular models. Here's a snapshot of supported models:
- OpenAI models (GPT-3.5, GPT-4)
- Anthropic Claude
- Azure OpenAI Service
- Google Gemini (via OpenAI-compatible interfaces)
- AWS Bedrock
Using Pydantic Models with instructor
You can also use standard Pydantic models with instructor for structuring LLM outputs. Here's how:
from pydantic import BaseModel
from instructor import patch
import openai
class UserModel(BaseModel):
name: str
age: int
patch(openai)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": "Tell me about John, age 30."}],
response_model=UserModel
)
print(response)
This approach allows you to combine the lightweight API of instructor with the validation power of Pydantic models, though it lacks the more aggressive error correction seen in pydantic-ai.
So, Which One?
Use pydantic-ai if:
- You're already neck-deep in a Pydantic-heavy codebase (and who isn't these days?).
- You need strict schema enforcement with minimal room for errors.
- Automated correction of invalid outputs is essential.
Use instructor if:
- You prefer a lighter touch with more flexibility.
- Your project values stability and a slower pace of change.
- You're working with more experimental or less critical data pipelines.
The Real Story: Adoption Curves
The star history tells a fascinating story. pydantic-ai is seeing explosive growth, likely due to the already massive adoption of Pydantic in the Python ecosystem and its ease of integration into existing data validation pipelines. Meanwhile, instructor's steady rise suggests a loyal base—but not a breakout trend.
The speed at which pydantic-ai has gained traction may also reflect the increasing demand for stricter validation as LLM usage scales into production environments. More developers are shifting from exploratory use cases to critical production pipelines, where schema violations can cause real damage.
Hype or not, both tools solve real problems. Pick your tool—you no longer have to ask your LLM to write JSON unassisted again.